18 min read
UPDATE December 21, 2019: After I put this post out, I re-ran the scan as part of routine follow up. The cookie mapping that was observed in the original scan and documented in this post is no longer present. It's not clear how or why this shift occurred, but at some point between the original scan, publishing this writeup, and a new scan completed after this writeup was published, the tracking behavior observed within Canvas has changed. More details are available here. END UPDATE.
Recently, a friend reached out to me with some questions about ad tracking, and the potential for ad tracking that may or may not occur when a learner is using a Learning Management System (or LMS) provided by a school. LMSs are often required by schools, colleges, and universities. LMSs hold a unique spot in student learning, effectively positioned between students, faculty, and the work both need to do to succeed and progress.
With the central placement of LMSs in mind, we wanted to look at a common use case for students required to use an LMS as part of their daily school experience. In particular, we wanted to look at the potential for third party tracking when students do a range of pretty normal things: check their personal email, search and find information, watch a video, and check an assignment for school. The tasks in this scan take a person about five to seven minutes to complete.
The account used for testing is from a real student above the age of 13 in a K12 setting in the United States. The LMS accessed in the test is Canvas from Instructure, and the LMS is required for use in the school setting. The full testing scenario, additional details on the testing process, and screenshots documenting the results, are all available below.
Summary and Overview
The scan described in this post focuses on one question: if a high school student has a personal GMail account and is required to use a school provided LMS with a school provided email, what ad tracking could they be exposed to via regular web browsing?
In this scan, we observed tracking cookies set on a person's browser almost immediately after logging into their consumer GMail account. These tracking cookies were used to track the person as they searched on Google and YouTube, and as they browsed a popular site focused on providing medical information. Because the GMail account used for the scan is a consumer GMail account, the observed tracking is not unexpected.
However, when the student logged into Canvas, the LMS provided by their school, using their school-provided email address which is not a GSuite account, we also observed the same ad tracking cookies getting synched to the LMS' Google Analytics tracking ID. This synchronization clearly occurred when the student was logged into the LMS.
This tracking activity raises several questions, but in this summary we will limit the scope to three:
- Why is a Google Analytics ID being mapped to tracking cookies that are tied to an individual identity and set in an ad tracking context?
- Why is the LMS -- in this example, Canvas -- using Analytics that potentially exposes learners to ad tracking?
These two questions lead into the third question, which will be the subject of follow up scans: given the large number of educational sites that also use Google Analytics, can similar mapping of Google Analytics IDs to adtech cookie IDs be observed on other educational sites?
The analysis of the scan is broken into multiple sections, and each section has a "Breakpoint" that summarizes the report.
- Testing Scenario: The steps used in this scan to allow anyone to replicate this work.
- Testing Process: The process used to set up for the scan.
- Results: The full results of the scan.
- Breakpoint 1: A summary of the process that sets the tracking cookies after a person logs in to a consumer GMail account.
- Breakpoint 2: Search activity on Google.
- Breakpoint 3: Ad tracking on the Mayo Clinic site.
- Breakpoint 4: Search activity on YouTube.
- Breakpoint 5: Mapping of Instructure's Google Analytics IDs to ad tracking IDs.
- Additional Scans: Follow up work indicated by this scan.
- Conclusions: Takeaways and observations from the scan.
Testing Scenario
The scan was run using a real GMail account, and a real school email account provisioned by a public K12 school district in the United States. The owner of both accounts is over the age of 13. The school email account was not a GSuite EDU account. The LMS used to run this test was Canvas from Instructure. The testing scan used these steps:
A. Consumer Google Account
- Log in at google.com
- Go to email
- Read an email
- Return to google.com
- Search for "runny nose"
B. Medical Information
- View the top hit from Mayo Clinic or WebMD
C. YouTube
- Go to YouTube.com
- Search for "runny nose"
- View the top hit for 90 seconds
- Watch one of the top recommended videos for 90 seconds.
D. School-supplied LMS in K12
- Go to Canvas login page and log in using a school-provided email address
- Navigate course materials (approximately 10 clicks to access assignments and notes)
- Return to student dashboard
- Log out of Canvas
Testing Process
The testing used a clean browser with all cookies, cache, browsing history, and offline content deleted prior to beginning the scan. The GMail account used had not modified or altered the default settings.
Web traffic was observed using OWASP ZAP, an intercepting proxy.
Results
In summarizing the results, we will focus on tracking that happens related to Google, and while logged in to Canvas. This analysis does not get into the tracking that Canvas does, or the tracking and data access permitted by Canvas via Canvas's APIs. For a good analysis of the tracking and access that Canvas allows via their APIs, read Kin Lane's breakdown of the data elements supported by Canvas's public APIs.
This post looks at one specific question: if a person is both browsing the web and using their school-provided LMS, what could tracking look like? The results described here provide a high level summary of the full scan; for reasons of focus and brevity, we only cover observed tracking from Google. Other entities that appear in this scan also get data, but Google gets data throughout the testing script.
In the scan, multiple services set multiple IDs. The analysis in this post highlights two IDs set by Google; these two IDs merit a higher level of attention because they are called across multiple sites, are mapped to one another, and are mapped to a separate Google Analytics ID connected to Canvas. In the scan, mapping Google Analytics IDs to IDs that appear to be connected to ad tech happens on both sites that use Google Analytics - the Mayo Clinic site, and the Canvas site.
To protect the privacy of the account used to run this scan, we obscure the IDs when we show the screenshots. The first ID will be marked by this screen:

The second ID is marked by this screen:

For privacy reasons, I also obscure the referrer URL and the user-agent string. The referrer URL shows the domain that was scanned, which in turn would expose the specific Canvas instance, which would compromise the privacy of the account used to run the scan. The user-agent string provides technical information about computer running the scan, including details about the web browser, version, and operating system. This information is the foundation of a device fingerprint, which can be used to identify an individual.
Step A. Consumer Google Account
Our scan begins with a person logging in to a personal GMail account.
Almost immediately after logging into GMail, the two tracking cookies are set. These cookies are set sequentially, and are mapped to one another immediately.
A call to "adservice.google.com" sets the first cookie. This initial request both sets a cookie (indicated by the value screened by "Tracker 1") and redirects to a second subdomain (googleads.g.doubleclick.net) controlled by Google:

Screenshot 1
And this is the response that sets the cookie:
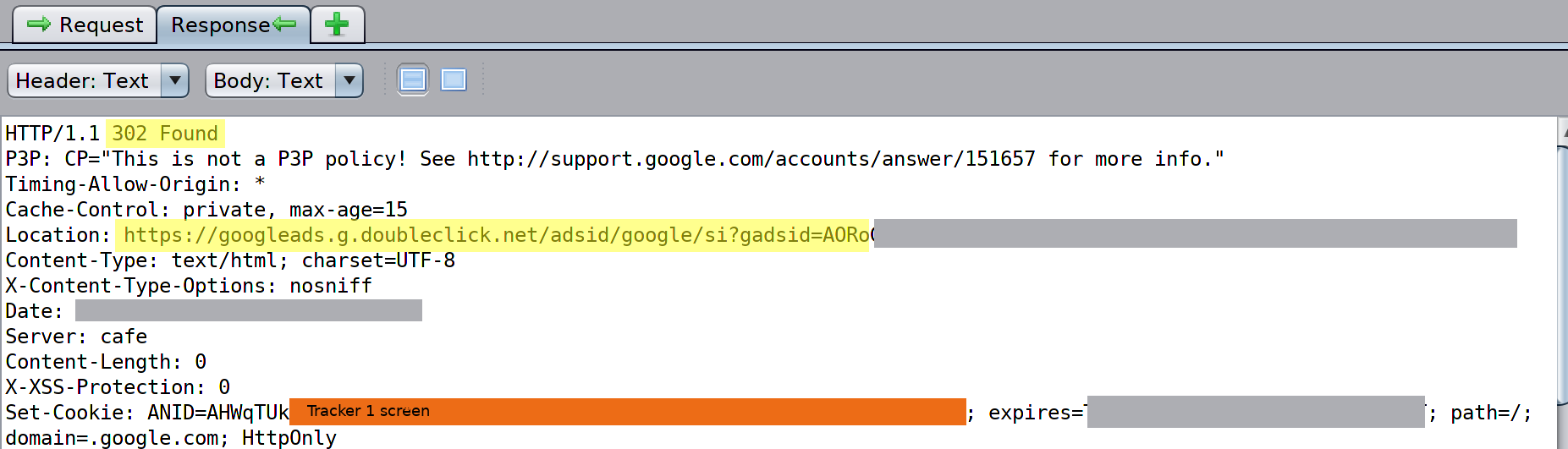
Screenshot 2
In the response shown above, three things can be observed/noted:
1. the initial request returns a 302 redirect that calls a new URL; 2. the location of the URL is specified in the "Location" line, highlighted in yellow; 3. the tracker value screened by "Tracker 1" is set via the "Set Cookie" directive.
The next event tracked in the scan is the get request to the URL (in the googleads.g.doubleclick.net subdomain) indicated in Screenshot 2.
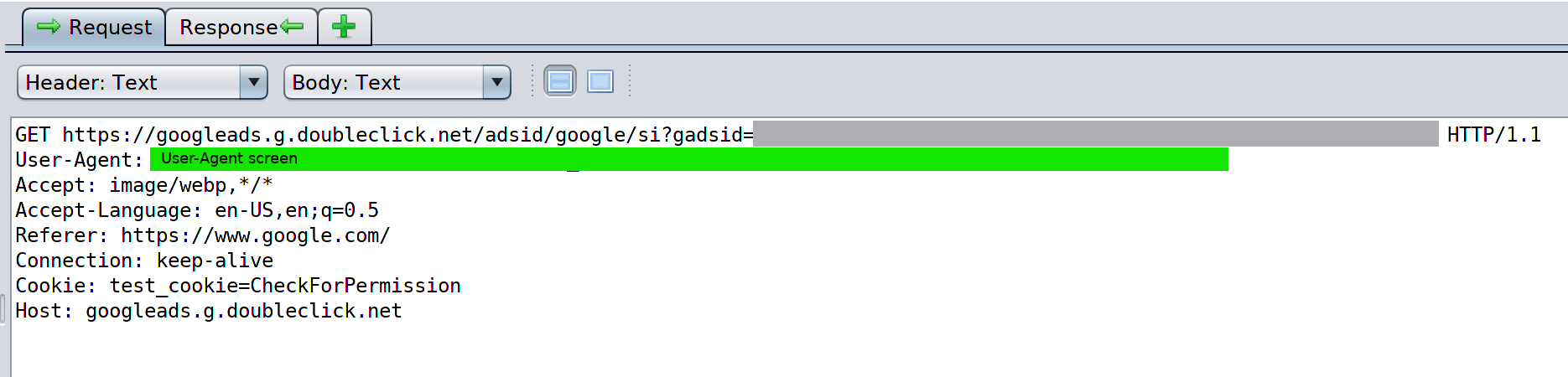
Screenshot 3
The screenshot below shows the response, including the directive to set the second tracking cookie (marked at "Set-Cookie").
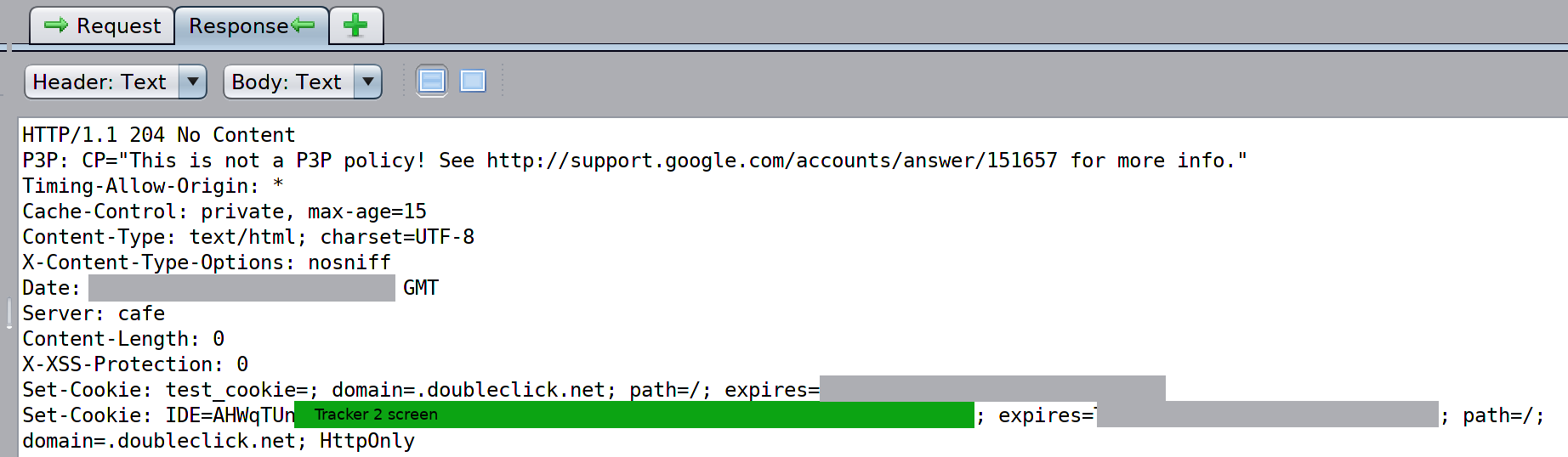
Screenshot 4
At this point in the scan, the two cookies (marked by the "Tracker 1" and "Tracker 2" screens) that will be called repeatedly across all sites visited have been set. As shown in the screenshots, these cookies are mapped to one another from the outset. These two cookies are set after a person logs into a GMail account, so they can be tied to a person's actual identity.
As we will observe in this scan, these cookies are accessed repeatedly across multiple web sites, and connected to a range of different activities and behaviors.
Breakpoint 1: Two tracking cookies have been set. The specific responses that set the cookies are shown in Screenshots 2 and 4. As the cookie values are initially set, the values are set to "IDE" and "ANID" and it's important to note that the cookies are almost certainly synchronized with one another via the 302 redirect used to set both values sequentially. When the first cookie value is set, the response header specifies the exact call that sets the second cookie value. In practical terms, this means that Google and Doubleclick both "know" that Tracker 1 and Tracker 2 correspond to the same person. Moreover, because these cookies are set after a person logs into their personal GMail account, these values are directly tied to a person's identity.
Google provides some partial documentation on the cookies they set and access:
We also use one or more cookies for advertising we serve across the web. One of the main advertising cookies on non-Google sites is named ‘IDE‘ and is stored in browsers under the domain doubleclick.net. Another is stored in google.com and is called ANID
As shown above in Screenshot 2 the ANID value (marked by Tracker 1) is accessible from within .google.com. As shown above in Screenshot 4, the IDE value (marked by Tracker 2) is accessible from within .doubleclick.net.
Search on Google
After reading the email, we returned to google.com to do a search for "runny nose." After all, it is the season for colds.
One thing to note for any search functionality that returns suggestions while you type: this functionality doubles as a key logger. For example, when searching for "runny nose" we can observe every keystroke being sent to Google in real time.
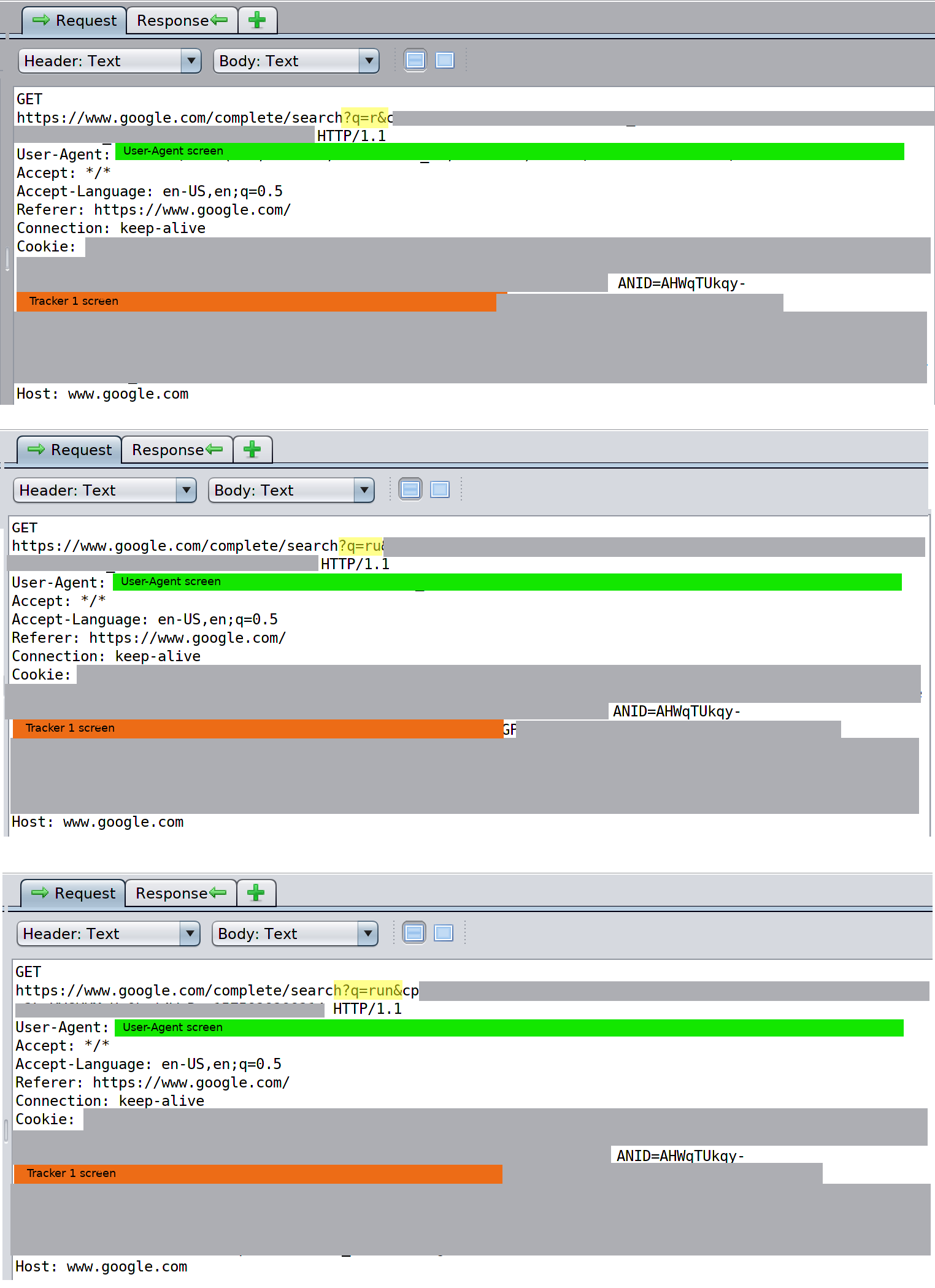
Screenshot 5
As shown in the above screenshot, every keystroke entered while searching is tied to the first tracking cookie documented in our scan. The text entered in the search box is highlighted in yellow, and we can observe each new keystroke being sent to Google, with the get request mapped to the cookie ID set in Screenshot 2.
Breakpoint 2: Search activity on google.com is (obviously) managed by Google. The full search activity, including individual keystrokes, is tracked and tied to Tracker 1.
Step B. Medical Information
The search for information about a runny nose leads to a page on the Mayo Clinic web site. Visiting this page kicks off some additional tracking and advertising-related behavior.
First, we see the Google Analytics ID for the Mayo Clinic site mapped to the second tracking cookie ID. The Google Analytics ID for the Mayo Clinic site, along with the referrer URL, are both highlighted in yellow.
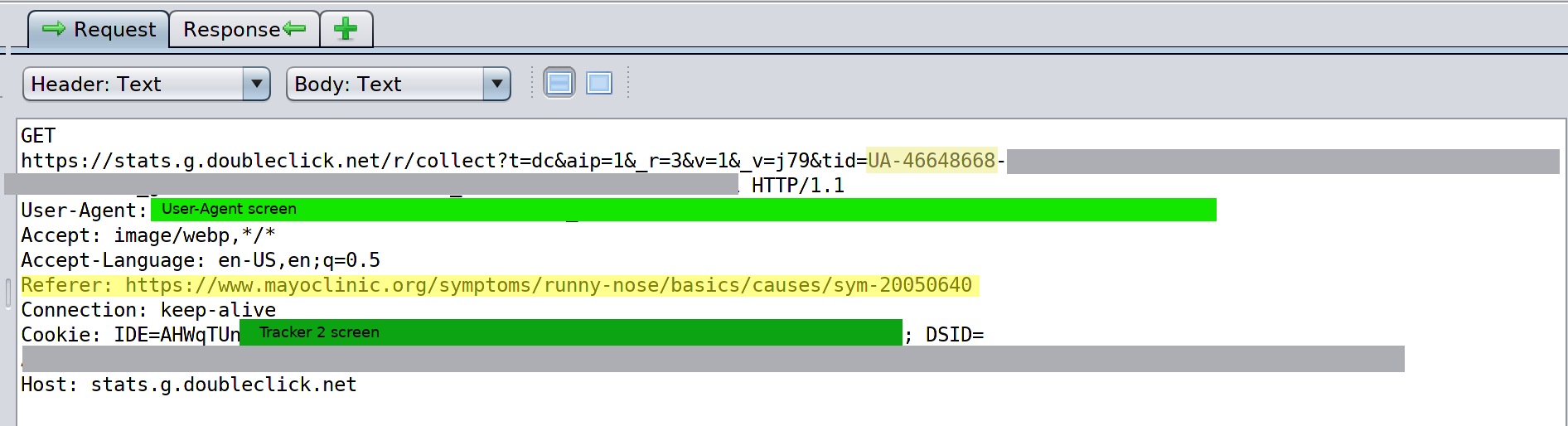
Screenshot 6
Then, we can observe what appears to be additional adtech and tracking-related behavior connected to this same tracking cookie ID
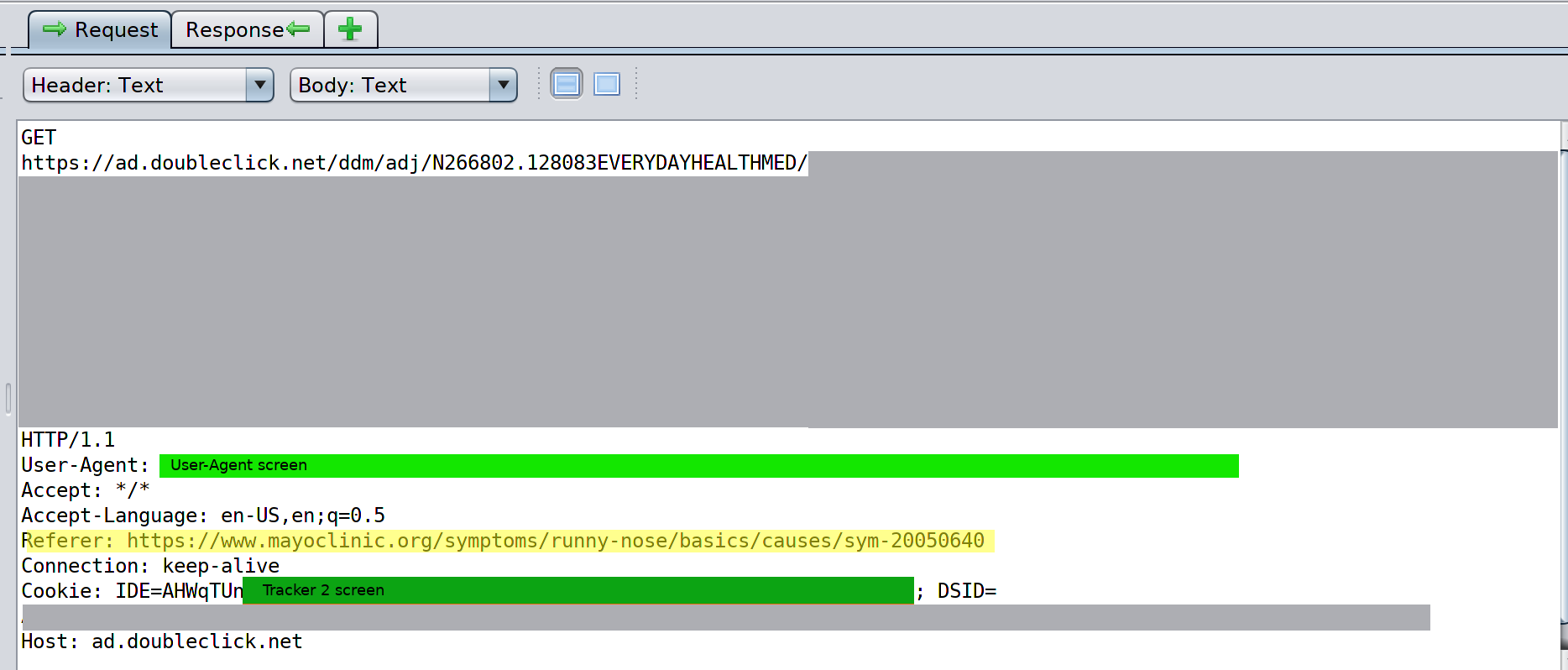
Screenshot 7
As we can see in the above screenshot, the referrer url is from the specific page on the Mayo Clinic web site. As noted above, the cookie IDs are mapped to a specific identity known to Google. Thus, Google knows when the account used for this scan searched for a specific piece of medical information, and accessed a web site about it. Because these tracking cookies were set when a person logged into GMail, this activity can be directly tied to a specific person.
Breakpoint 3: when a person moves off a Google property, the tracking switches to Tracker 2, which can be read by Doubleclick. Screenshot 6 shows Tracker 2 being mapped to the Google Analytics ID of Mayo Clinic. Screenshot 7 shows additional ad related behavior connected to Tracker 2. In this section, we can observe two additional subdomains; stats.g.doubleclick.net (often connected to Analytics) and ad.doubleclick.net (generally connected to ads). It is not clear why the Tracker 2 value, which was clearly set in an advertising/tracking context, needs to be mapped to a Google Analytics ID.
Step C. YouTube
After visiting the Mayo Clinic web site, the scan continued on YouTube. Here, we searched for a video about a "runny nose" and watched the video.
As noted above when searching using Google, YouTube search also functions as a key logger, and ties the results to a cookie ID that is directly connected to a person's real identity.
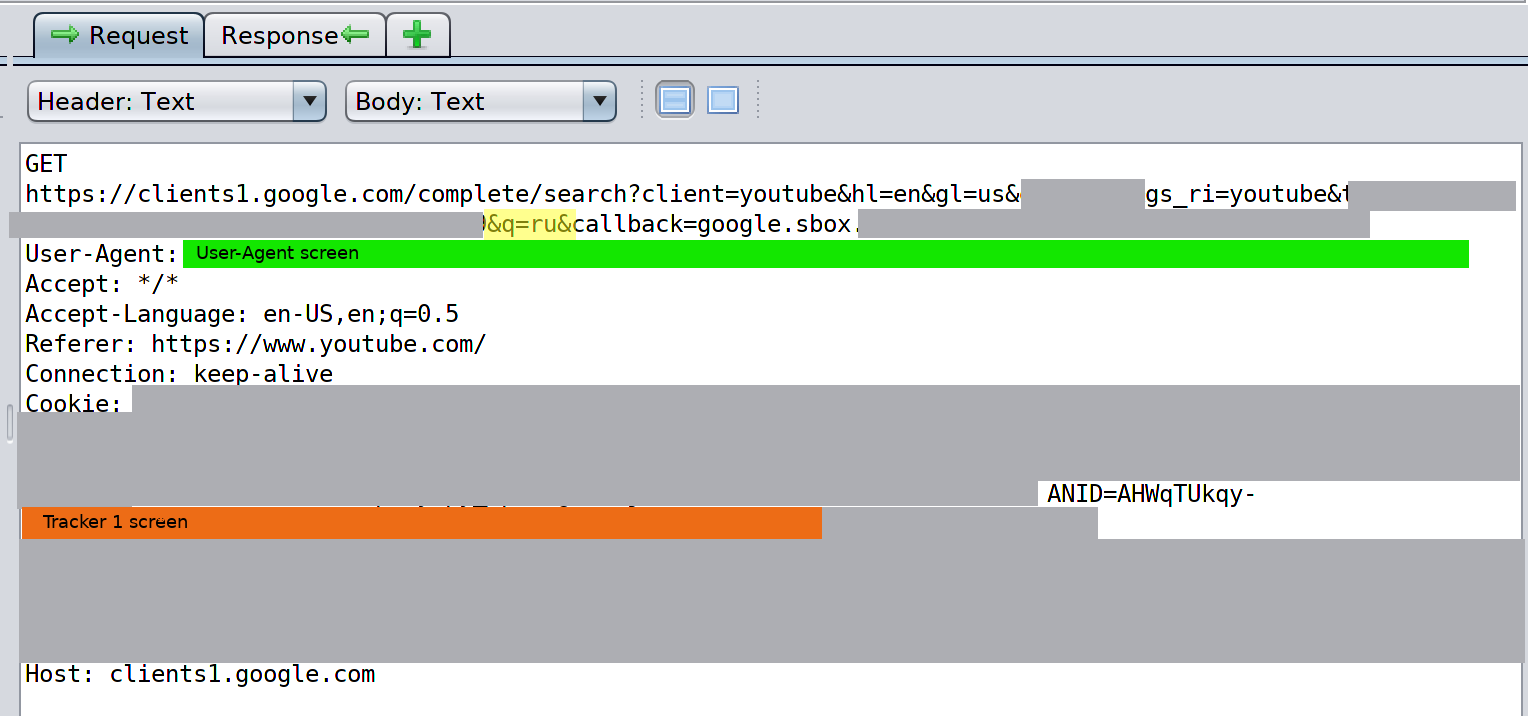
Screenshot 9
Screenshot 9 shows the "ru" of the eventual search query "runny nose". As shown in Screenshot 5 related to searching on Google, a request is sent for every keystroke, including spaces and deletions.
Breakpoint 4: Search activity within YouTube is managed by Google. As with search on google.com, the full search activity, including individual keystrokes, is tracked and tied to Tracker 1.
Step D. School-supplied LMS
After searching for and watching a video about a runny nose, the scan proceeded to log in to a K12 instance of Canvas.
For this scan, the person logged into the LMS with a school-provided email account. The school provided email account was not provisioned from a GSuite for EDU domain. The email address was from a domain connected to a K12 school district connected to a student account.
After the person logs into Canvas, both cookie IDs are mapped to Instructure's Google Analytics ID. The mapping occurs via 302 redirects, with the Analytics ID contained in URL calls that include the Cookie IDs in the request headers. The process is documented in the screenshots below, and is similar to the mapping that occurred while browsing the Mayo Clinic web site.
The referring URL is clearly a course within the LMS. The Google Analytics ID (UA-9138420) that belongs to Canvas/Instructure is highlighted in yellow.
The first call is to stats.g.doubleclick.net. As you can see in the screenshot below, the request includes the Google Analytics ID and the tracking cookie in the request header. The response returns a redirect that also includes the Google Analytics ID.
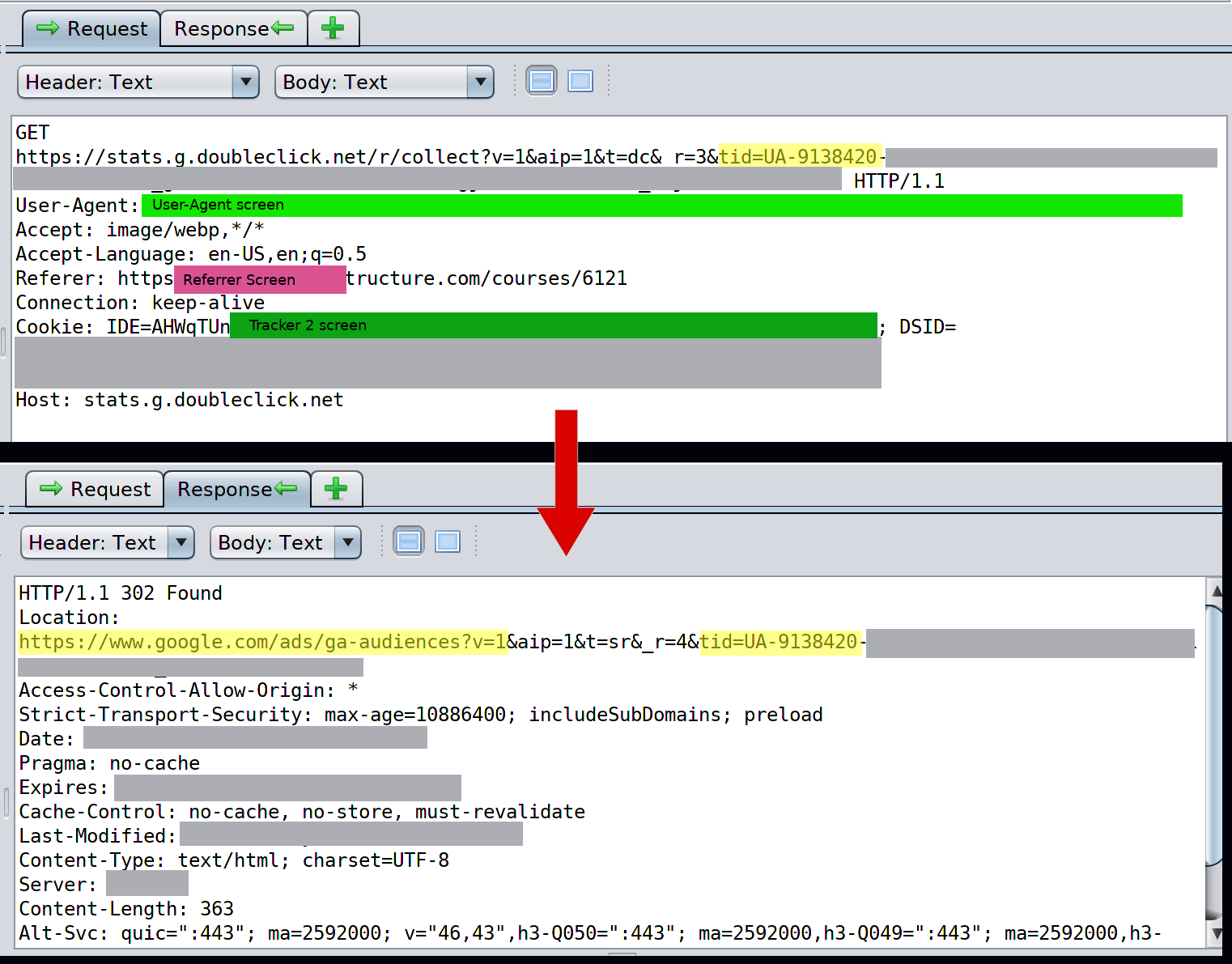
Screenshot 10
As shown in Screenshot 10, the URL specified by the redirect points to google.com/ads. The redirect also contains the Google Analytics ID for Instructure.
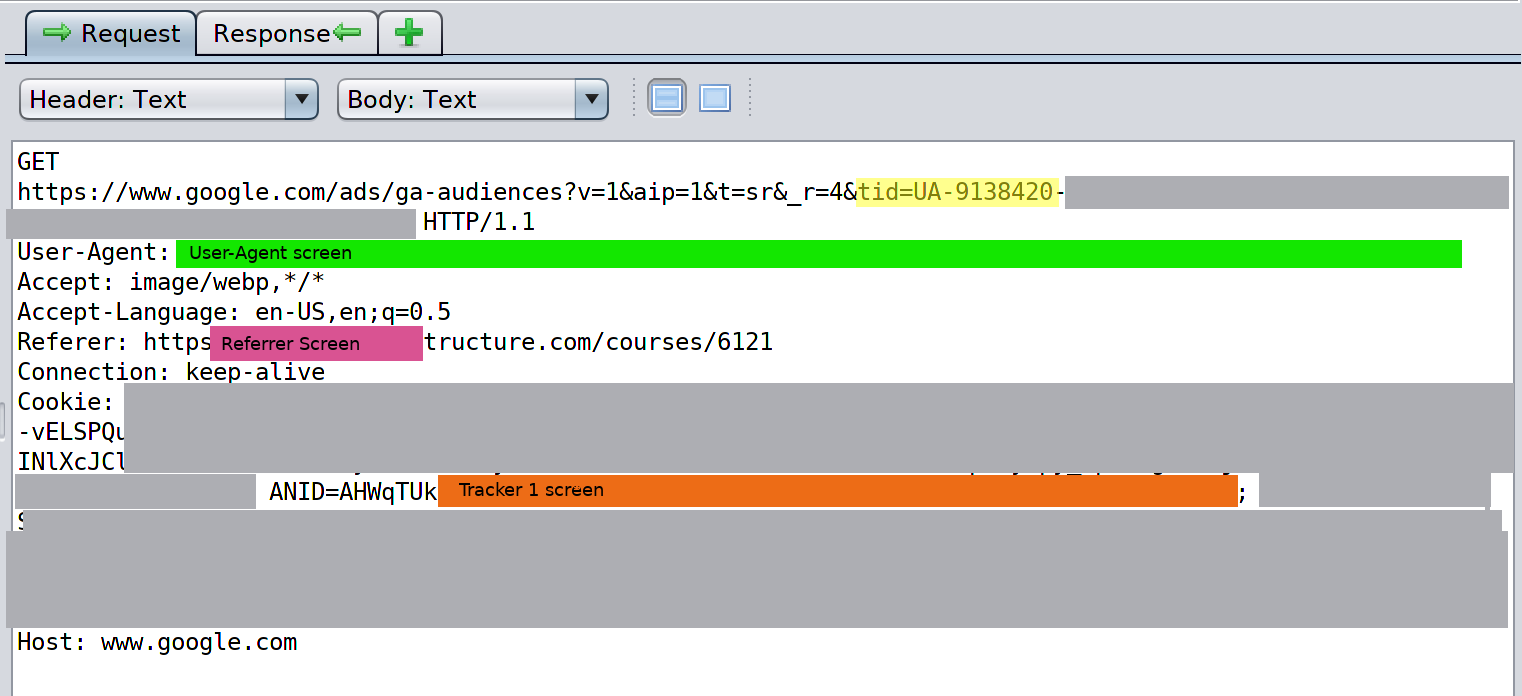
Screenshot 11
As described and shown in Screenshots 10 and 11, these two calls map both cookie IDs to Instructure's Google Analytics ID. To emphasize, both of the cookie IDs mapped to Instructure's Google Analytics ID are also directly connected to a personal GMail account that is tied to a person's identity.
Breakpoint 5: While logged into a school-provided (and required) LMS, both Tracker 1 and Tracker 2 are mapped to the Google Analytics ID of the LMS. This means that the same advertising IDs that are tied to a specific student's identity, tied to browsing history on a site with medical information, and tied to search history on Google and YouTube, are also tied to the Google Analytics ID of an EdTech vendor. In practical terms, this means that Google could theoretically incorporate general LMS usage data (time on site, time on page, pages visited, etc) into their profiles of learners and/or educators.
Visiting Subdomains
Visiting the subdomains called when the cookies were mapped to Instructure's Analytics ID returns web sites that appear to serve advertisers.
Attempting to visit google.com/ads redirects to a page that clearly appears to be connected to advertising:
Screenshot 12
Attempting to visit stats.g.doubleclick.net redirects to a page that offers services for analytics related to Google Marketing Platform.
Screenshot 13
A look at the features overview page shows that there is a "native data onboarding integration" with Google Ads and Adsense, and "native remarketing integrations" with Google Ads.
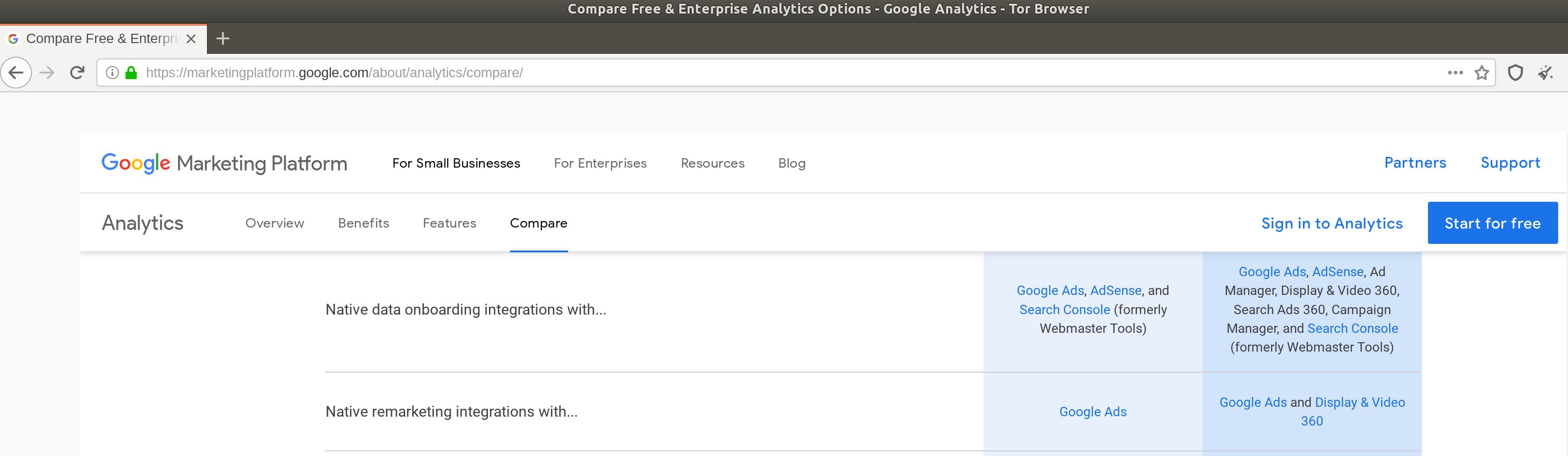
Screenshot 14
Additional Areas for Examination
This initial scan was limited in scope to test one specific -- yet common -- use case: what does ad tracking look like when a person has a consumer GMail account, and uses the same browser to access that personal account as their school-provided LMS? With this initial scan in place, several follow up tests would help create a more complete picture.
- Use a school-provided Gmail account.
- Visit other sites with ads and observe other ad-related interactions that are mapped to either of these cookies.
- Test other LMSs that use Google Analytics to see if there is comparable mapping of Google Analytics IDs to cookie IDs.
- Test other educational sites that use Google Analytics to see if there is comparable mapping of Google Analytics IDs to cookie IDs.
These scans would each provide additional information that would help create a more complete picture, and would build on and provide additional context to what was observed in this initial scan. If the mapping observed in this scan is replicated across the web on other educational sites that use Google Analytics within K12 or higher ed, then -- theoretically -- students could be profiled based on their interactions with sites they are required to use for school. The types of redlining, targeting, or "predictions" that would be possible from this type of profiling are clearly not in the best interests of learners.
Conclusions
This scan covers a pretty common use case: a person who checks their personal email and searches for other information, and then does some schoolwork. As documented in this writeup, this behavior results in a range of tracking behavior that includes:
- a. tracking cookies are set shortly after a person logs into a Google account, and these cookies are directly tied to a person's specific identity;
- b. via these cookies, Google gets specific information about searches on YouTube and Google, including keylogging of the search process;
- c. via these cookies, Google gets specific information about the sites a person visits, and when they visit them;
- d. on both sites in this scan that used Google Analytics, the domain's Google Analytics ID was synched with tracking cookies;
- e. while logged in to an LMS as a high school student, the Google Analytics ID of the required LMS for a public high school student is mapped to cookie IDs that appear to be used for ad targeting, and are tied to a student's real identity.
It is not clear why Instructure's Google Analytics ID needs to be mapped to cookie IDs that are set in a consumer context and appear to be related to ad tracking.
To be very clear: the tracking cookies mapped to a person's actual identity occurred within the context of consumer use. When a person uses Gmail, or searches via Google, or browses a site for medical information, they are tracked, and they are tracked in ways that can be connected back to their real identity. This is how adtech works, and -- based on current privacy law in the United States -- this is completely legal.
As observed in this scan, the tracking cookies set in a consumer context are also accessed when a student is logged into their LMS, in a strictly educational context. In practical terms, the only way for a high school student to completely avoid the type of tracking documented in this scan would be to practice abnormally strong browser hygiene -- for example, they could set up a separate profile in Firefox that they only used while accessing the LMS. But realistically, the chances of that happening are slim to none, and "solutions" like this put the onus in the wrong place: a high school student should not be required to fix the excesses of the adtech industry, especially when they are accessing the required software that comes as a part of their legally required public education.
